Daten sind abstrakt und oft schwer verständlich. Dennoch bergen sie wertvolle Informationen. Wieso ist es so schwierig, diese Informationen zu gewinnen und zu kommunizieren?
Viele komplexe Systeme, mit denen wir es heute zu tun haben, wie zum Beispiel Produktionsprozesse oder die Kundenreise (Customer Lifetime Journey), sind größtenteils unsichtbar. Nur über den Umweg des Datensammelns und der Datenanalyse haben wir die Chance, diese Systeme so weit zu verstehen, dass wir Probleme erkennen und lösen können.
Datenvisualisierungen sind der freundliche Zugang zu diesen Daten. Sie sollen es auch Nicht-Techies ermöglichen, Daten zu lesen und zu interpretieren.
Die bunte und ansprechende Aufmachung verleitet uns allerdings dazu zu denken, dass alles einfach ist und nichts mehr schiefgehen kann.
Ganz so einfach ist es allerdings nicht. Datenvisualisierungen werden sehr oft nicht verstanden. Wenn Sie das schon mal beobachtet haben, entweder als Leser oder als Ersteller von Visualisierungen, dann sollten Sie jetzt weiterlesen.
Nach meiner Beobachtung kann leider eine ganze Menge schiefgehen. Seit über zehn Jahren entwickle ich User Interfaces für Datenprodukte und ich habe die schmerzhafte Erfahrung gemacht, dass Visualisierungen oft ihren Zweck nicht erfüllen. Die Nutzer verstehen die visuelle Sprache nicht, können die Datenstruktur nicht erfassen, oder die Bedeutung der präsentierten Daten nicht erschließen. Bei einigen besonders ehrgeizigen Business Intelligence Projekten mussten wir feststellen, dass die Visualisierungen hinterher kaum benutzt wurden. Aber woran liegt das? Und wie kann man es besser machen?
All diese Fragen beantwortet unser Data Design Guide, den wir basierend auf unseren praktischen Erfahrungen entwickelt haben. Er erläutert systematisch die nötigen Schritte für die erfolgreiche Visualisierung von Daten.
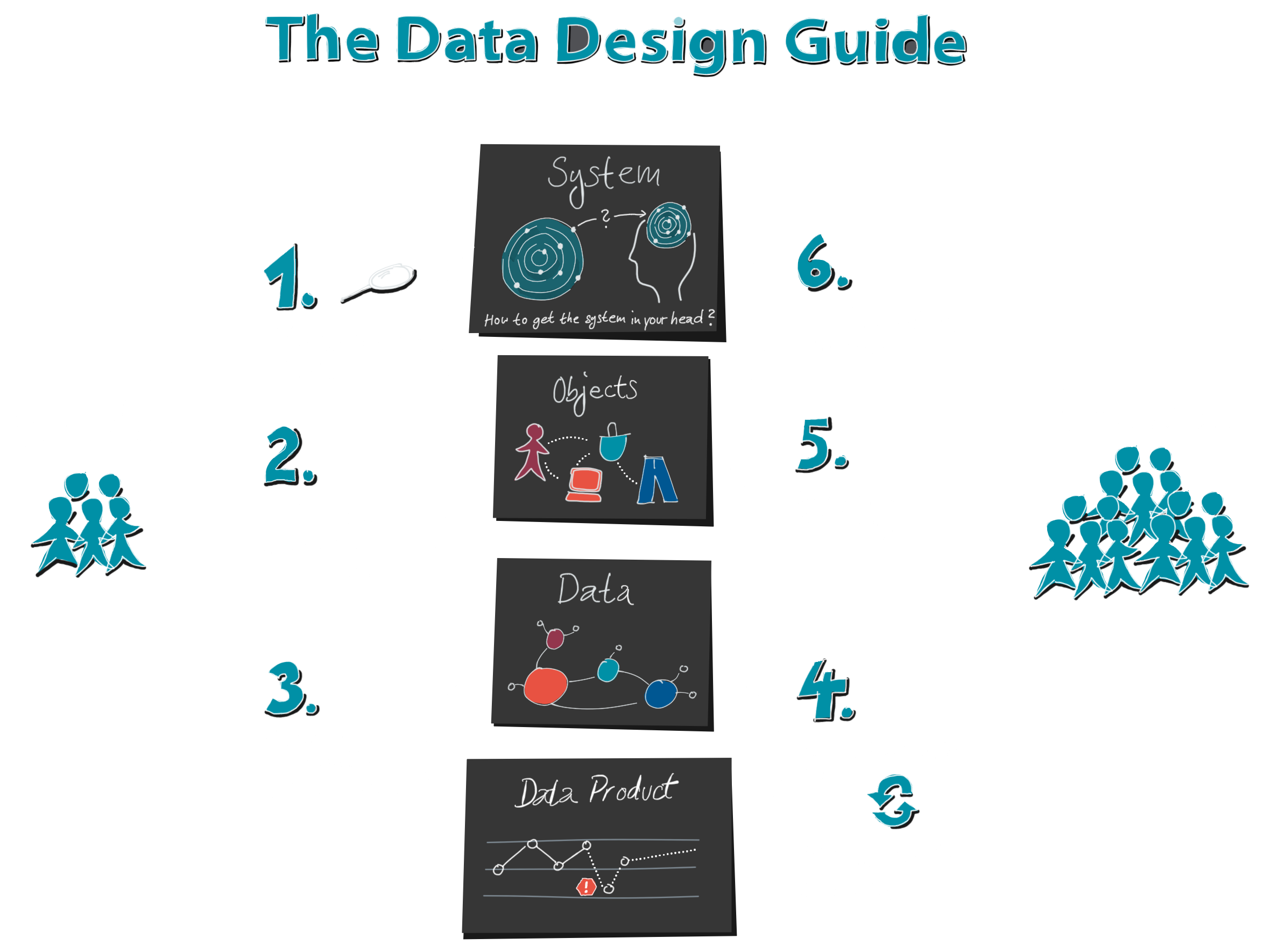
1. Schauen wir uns doch mal den Prozess an, wie Datenvisualisierungen erstellt werden. Dieser beginnt nicht, wie oft angenommen, bei den Daten.
Er beginnt schon viel früher, nämlich mit dem dahinter liegenden System.
Denn hinter allen Daten liegt ein System in der echten Welt. Meist ist es unsichtbar und sehr komplex. Nehmen wir zum Beispiel einen Webshop. Niemand kann die Besucherströme einfach so sehen.
Zuerst brauchen wir eine Vorstellung, eine mentale Karte dieses Webshops, um zu entscheiden, welche Objekte, Eigenschaften und Ereignisse wir messen wollen: Besucher, Webseiten, Warenkorb und Produkte, es gäbe vieles, was interessant wäre. Aber nicht alle Dinge können wir technisch gesehen messen, wie z.B. die Gedanken eines Webshop-Besuchers, während er sich entscheidet, ein Produkt in seinem Warenkorb doch nicht zu kaufen. Wie schön wäre es, das zu wissen!
Ebenso könnte unsere mentale Karte unvollständig, ungenau oder schlicht falsch sein. Dann stellen wir möglicherweise nicht die richtigen Fragen und messen nicht die richtigen Daten.
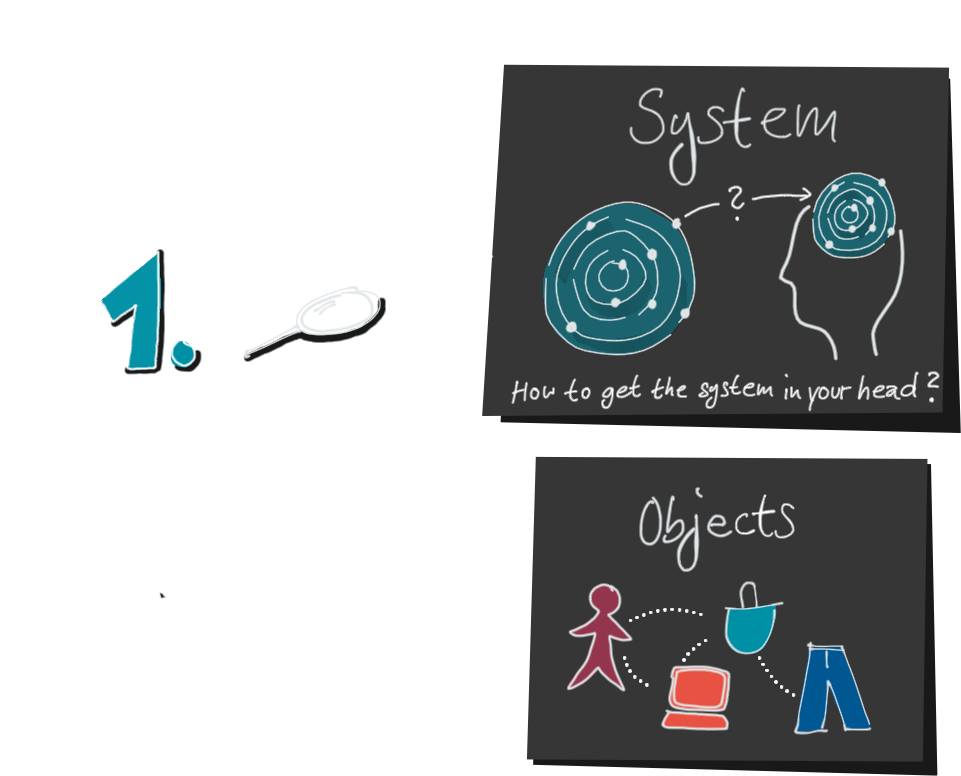
2. Als nächstes erstellen wir ein Datenmodell. Auch hier geht wieder einiges verloren, denn ein Datenmodell kann nicht jedes Detail der echten Welt aufnehmen. Wer das schon mal gemacht hat, der weiß: ein aufgeblasenes Datenmodell ist ein gefährliches Ungetüm. Deshalb bleiben wir lieber so einfach wie möglich und lassen unwichtige Details weg.
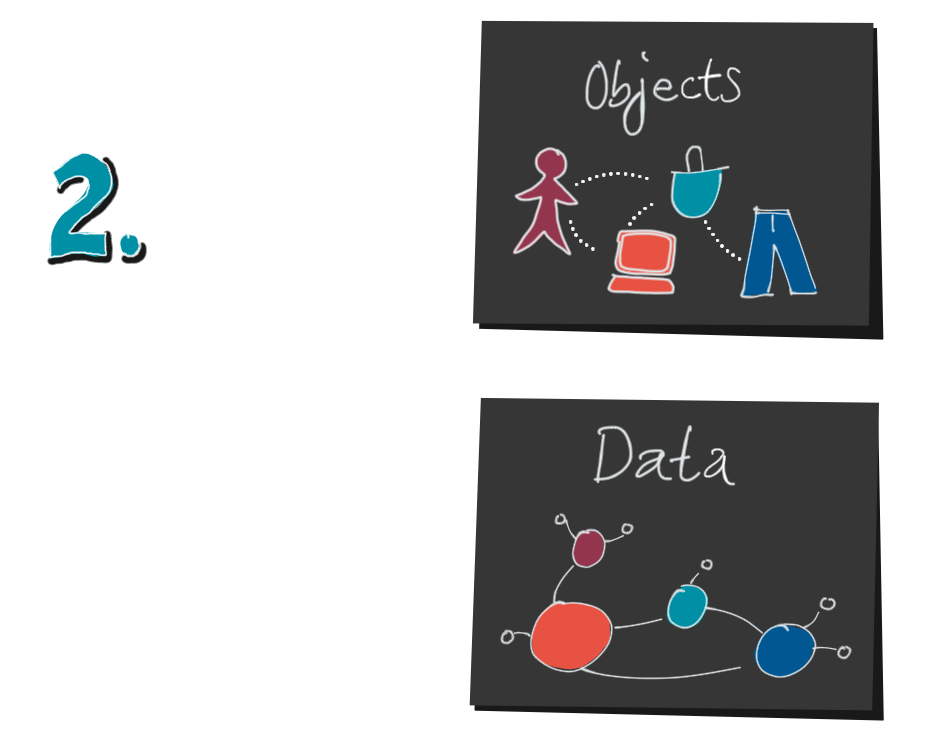
3. Nachdem wir Daten gesammelt und sie aufbereitet haben, erstellen wir endlich unsere Visualisierung. Bis zu diesem Schritt sind zwei Dinge passiert, die wir im Hinterkopf behalten sollten:
Erstens ist nicht die gesamte Komplexität des Systems in der Visualisierung sichtbar, und zweitens haben wir das System zweimal verschlüsselt.
Einmal wurde es in die Daten übersetzt, und dann wurden die Daten in die Visualisierung übersetzt. Daher nennen wir diesen Prozess auch Encoding und die Produzenten von Datenvisualisierungen Encoders.
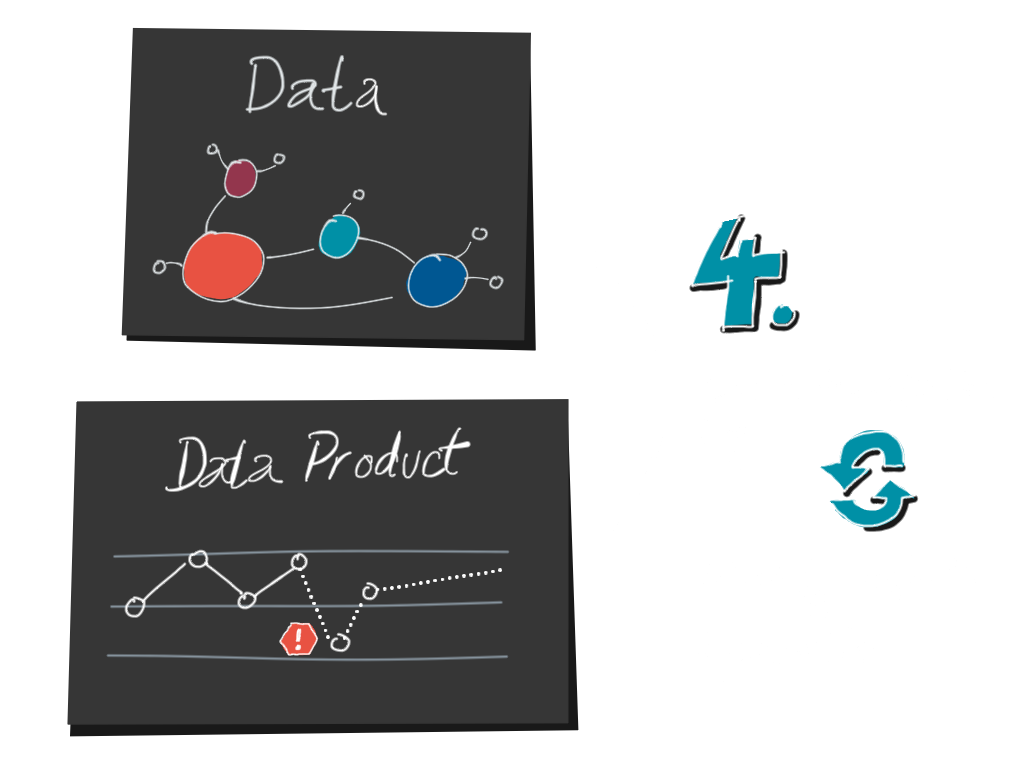
4. Und, sind wir jetzt fertig? Mitnichten, denn jetzt kommt die zweite Hälfte, das Dekodieren. Ein Decoder ist ein Leser einer Visualisierung.
Um das System zu verstehen und um handlungsrelevante Einsichten zu erhalten, muss der Decoder den eben beschriebenen Weg wieder rückwärts gehen:
von der Datenvisualisierung zu den Daten, und von den Daten zum mentalen Modell. Er möchte sein eigenes mentales Modell mit Hilfe der Daten bestätigen, präzisieren oder ändern. Wie kann ihm das gelingen?
Im ersten Schritt muss der Leser den Übersetzungsschlüssel knacken. Was bedeuten die Linien, die Punkte, die Position und Farbe? Was sagt die Achsenbeschriftung und die Legende? Gleichzeitig versucht er, die Datenstruktur zu erkennen. Diese Punkte in der Timeline, sind das Clicks pro Stunde pro Land? Oder doch pro Produkt?
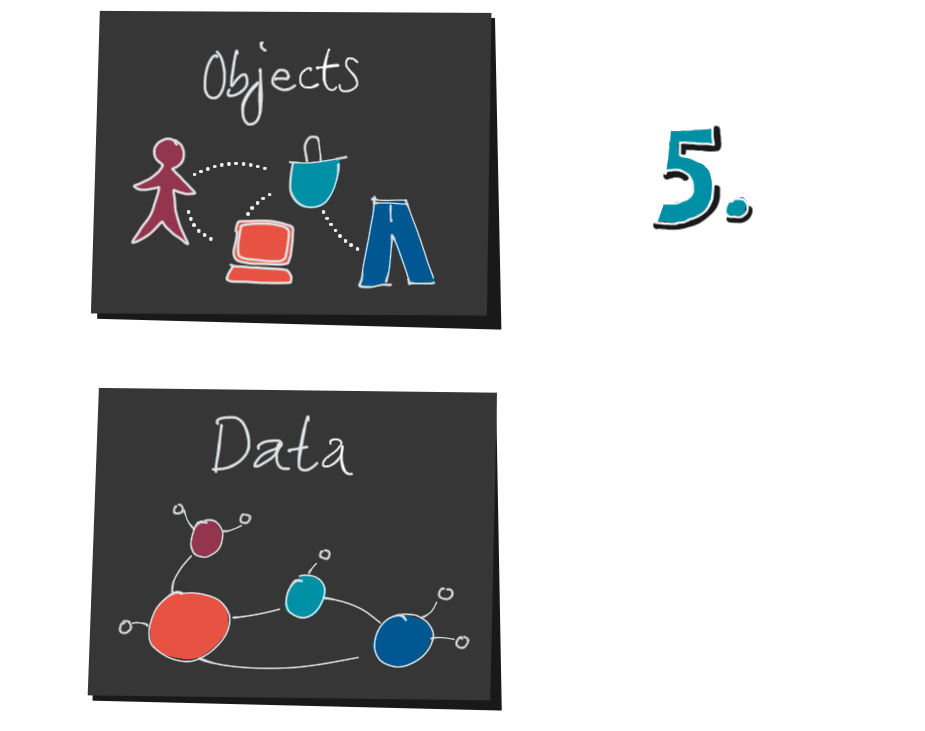
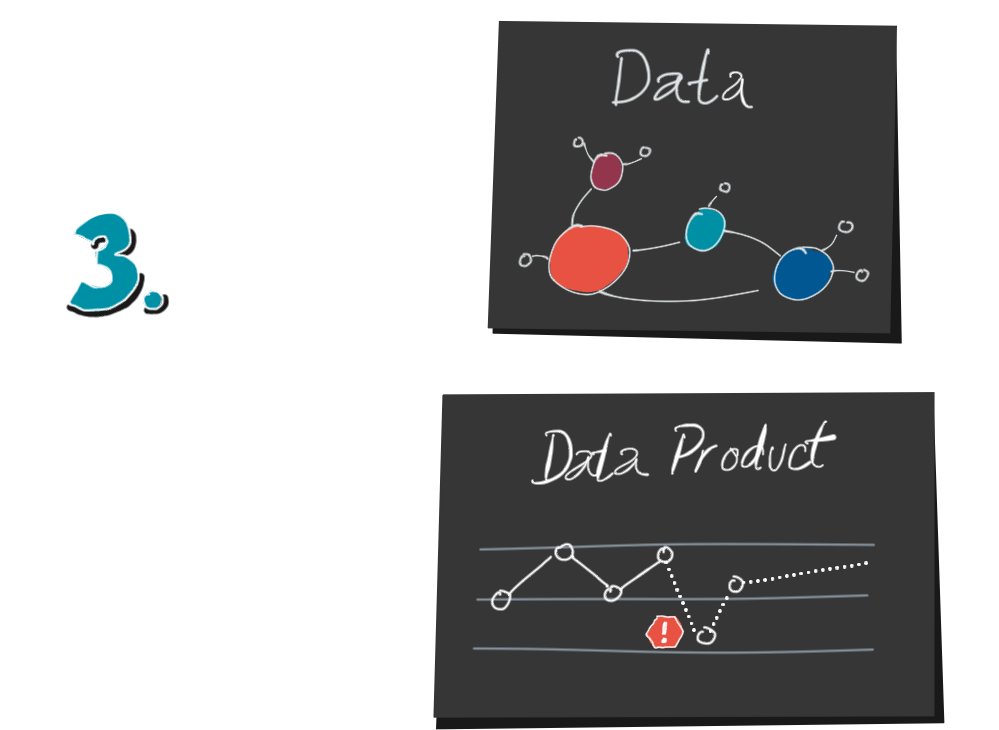
5. Sobald es ihm gelungen ist, die Datenstruktur zu entschlüsseln, kann er sich ein Bild von den Objekten machen. Dazu sind statistische Kenntnisse hilfreich. Sind das absolute oder relative Zahlen? Wie groß ist die Grundmenge? Wie sind die Mengenverhältnisse und Beziehungen zwischen Jeans, Kleidergrößen und Bestellungen?
Diese Informationen sind rein quantitativ. Er weiß, dass etwas passiert ist, aber nicht warum. Warum verkaufen wir so viele Jeans in Übergrößen? Warum haben wir letzten Samstag 17% mehr Verkäufe als durchschnittlich an Samstagen? Hier kommt sein Domänenwissen, seine mentale Karte des Systems ins Spiel. Der durch das Encoding verloren gegangene Kontext muss wieder hinzugefügt werden.
Denn wir können Daten nicht interpretieren ohne Kausalität.
Wir brauchen Detailwissen, entstanden aus eigenen Erfahrungen und Geschichten. Wir Menschen sind Kausalitätsmaschinen. Daten ohne Kontext bleiben für uns bedeutungslos.
Eine gesunde Portion kritisches Denken gehört auch dazu. Welche Motive hatte der Autor? Welche Daten fehlen? Können die Daten stimmen? Gab es Messfehler? Gibt es Unsicherheiten? Habe ich selber eine Wahrnehmungsverzerrung? Welche Aussagen kann ich daraus ableiten, und welche nicht?
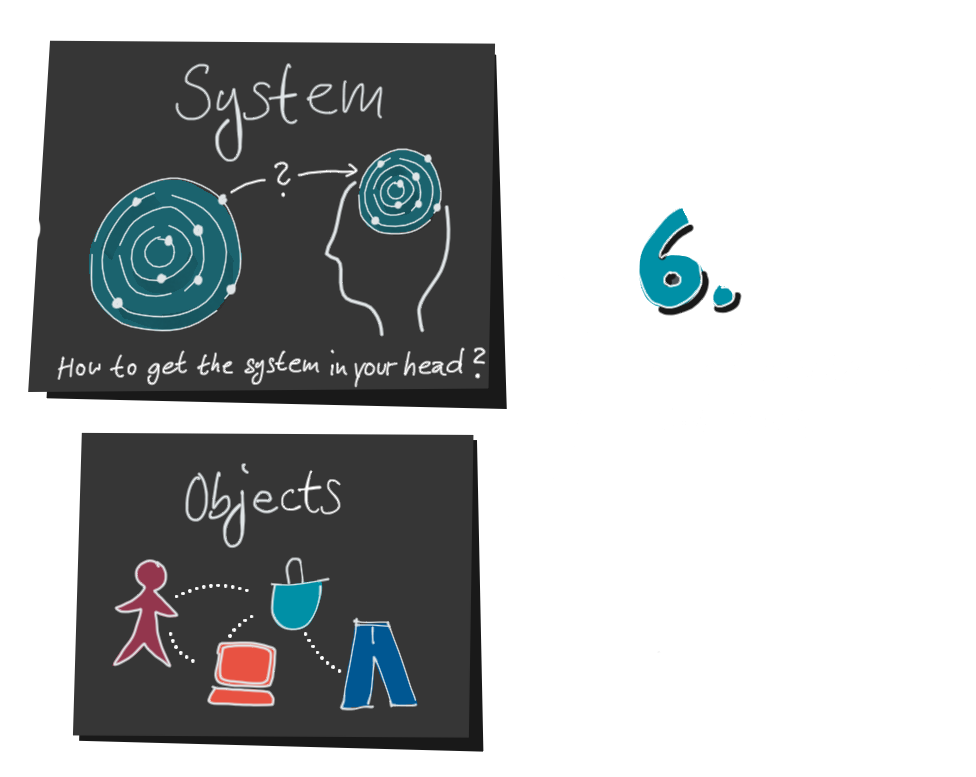
6. Wenn Daten und mentales Modell zusammenpassen, kann der Decoder jetzt die Daten interpretieren und tatsächlich umsetzbare Erkenntnisse gewinnen. Er kann sein Wissen erweitern und seine mentale Karte verbessern, oder aber weitere gezielte Fragen stellen.
Wie wir jedoch gesehen haben, ist der Weg bis hierhin weit. Es lauern viele Gefahren.
Nur derjenige, der den kompletten Prozess im Auge behält und auch die Leser unterstützt, wo sie es benötigen (Datenkompetenz und Data Literacy), wird ein erfolgreiches Datenprodukt oder eine effiziente Visualisierung bauen können.
Edit 21.10.2019
Es freut mich, dass der Data Design Guide Eingang in die Studie „Future Skills: Ein Framework für Data Literacy“ vom Hochschulforum Digitalisierung gefunden hat. Er dient als Grundlage des dort erarbeiteten Frameworks für Datenkompetenz.
„Analog zu Bewertungskriterien für Sprachkenntnisse unterscheidet der hier entwickelte Kompetenzrahmen zwischen Kodierungs- und Dekodierungsprozessen.“
A Designation brand
The Chart Doktor
Data Design Academy
Learn how to turn your users into real fans with impactful data visualizations. Learn how to design groundbreaking data products that people can’t live without.